Database Index
1. 인덱스란?
데이터베이스에서 원하는 데이터를 검색하기 위해서는 Full-Scan, 인덱스를 통한 검색이 가능하다. DB의 데이터는 삽입된 순서로 정렬되지 않은 형태로 물리적으로 저장되기 때문에 인덱스가 없을 경우 Full-Scan을 통해 자료를 찾아야 하는 비용 발생이 생긴다. n의 시간이지만 데이터가 수억 단위를 넘어가면 효율이 매우 떨어지게 된다.
2. 클러스터드 인덱스 vs 넌클러스터드 인덱스
- 클러스터드 인덱스 : 데이터베이스 테이블에 Only 1개만 지정될 수 있는 인덱스이다. 보통 Primary key로 지정하면 이 컬럼은 자동적으로 클러스터드 인덱스가 되어 물리적으로 자동 정렬된다.
클러스터드 인덱스는 정렬되어 있기 때문에 테이블 자체가 인덱스이다.
- 넌 클러스터드 인덱스 : 데이터베이스 테이블에 여러개 지정 할 수 있는 인덱스로 보통의 인덱스를 지칭한다. 일반적으로 책을 찾아볼 때 앞의 목차를 통해서 찾아가는 것과 같이 인덱스를 통해 데이터의 위치가 있는 곳을 찾아간다.
3. 인덱스의 동작 과정
- 데이터베이스의 테이블은 생성시 frm, myd, myi 로 나뉘어 저장되게 된다.
- frm : 테이블의 구조가 저장되어 있는파일
- myd : 테이블의 실제 데이터가 들어있는 파일
- myi : Index 정보가 들어있는 파일

사용자가 DB에서 데이터를 찾기 위해 select * from employee where salary>=3000; 이라는 쿼리를 입력했다고 하자.
1. DB는 이 테이블의 myi 파일에 salary에대해 인덱스가 있는지 확인한다.
2. 있을 경우 -> DB의 인덱스 파일을 기준으로 데이터블록을 찾는다.
없을 경우 -> Full Scan을 통해 조건에 해당하는 컬럼을 모두 검색한다.
4. 인덱스의 구조

이진 검색 트리
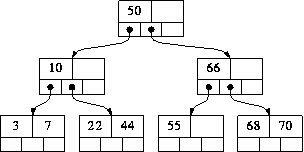
B tree
인덱스는 데이터의 저장이 B-TREE라는 자료구조로 저장되어 있다. 현재는 B-TREE의 많은 부분이 보완된 B+ TREE가 사용된다. B-TREE는 Balacned Tree의 약자로서 자동으로 균형을 맞추어 검색할 수 있는 트리이다.
일반적으로 트리는 검색을 위하여 균형을 맞추는 것이 중요하다. 이진 트리의 경우 일반적으로 검색 속도가 log n 의 시간복잡도를 가지지만 자식이 한쪽으로 편중된 경우 n의 시간을 갖기 때문에 검색속도에 대해서 효율을 얻을 수 없고 트리를 구성하는 비용에 대해 오히려 일반 배열보다 손해를 본다.
일반적인 이진 검색 트리는 노드의 자식 수가 2개로 제한된다는 점이 있지만 B-Tree는 자식을 최대 m개 까지 가질 수 있는 m원 탐색 트리를 기반으로 설계되었고 자동으로 균형을 맞추어 준다.
B-TREE -> B tree 참고
인덱스는 이렇게 B-Tree의 구조로 구성되어 있어서 루트 -> 브랜치 노드 브랜치 노드 -> 리프 노드의 순으로 검색을 계속해 나간다. 리프노드에 다다르면 해당 key에 대한 물리 데이터의 주소가 저장되어 있어 이를 통해 데이터에 쉽게 찾아 갈 수 있다.
4. 인덱스의 장단점
- 인덱스의 가장 큰 장점이라고 하면 검색 속도이다. 인덱스를 구성하면 적절한 인덱스를 선택하여 검색했을 때 일반적으로 Full Scan해서 검색하는 것보다 상당히 빠른 검색효율을 보일 수 있다.
- 하지만 인덱스는 검색 속도라는 장점을 가진 대신 단점도 많이 가지고 있다.
1. 인덱스 파일을 구성하는데에 비용이 들고 용량을 차지 하게된다.
-> 실질적으로 데이터가 삽입되면 데이터에 대한 인덱스 또한 추가해주어야 하기 때문에 비용이 들고 이 인덱스 파일을 구성하는데에 용량을 차지하게 된다.
#####2. DML(Insert, delete)에 약하다.
->데이터 변경 작업(Insert,delete)가 자주 일어날 경우 인덱스를 재작성해야 한다.
-> insert는 data가 저장되어 있는 기존 블록에 여유 공간이 없는 상황에서 그 블록에 새로운 데이터가 입력되어야 할 경우 블록을 새로 할당하고 기존에 있던 블록의 key value들을 옮기는 과정들을 수행하기 때문에 매우 많은 비용을 소모하게 된다. (Index Split)
-> delete의 경우 데이터가 삭제되면 인덱스파일은 데이터가 삭제되지 않고 사용되지 않음으로 표시된다. 100만이었던 데이터를 지워 10만개 남았더라도 인덱스는 100만건이 존재하므로 인덱스를 사용해도 수행속도를 기대하기 힘들 수 있다.
#####-> update의 경우 인덱스에 update라는 개념이 없으므로 테이블에 update가 발생할 경우 인덱스에는 delete, insert 두가지 작업이 실행되므로 가장 큰 부하를 일으킨다.